ネットワーク
目次
- 概要
- ネットワークの歴史
- 層に分ける理由
- OSI参照モデルとTCP/IPの対応
- 物理層とリンク層
- ネットワーク層(IPv4・IPv6)
- ルーティングプロトコル
- パケットとルーティング
- トランスポート層の概観
- TCPの詳細
- UDPの詳細
- ソケットプログラミング
- DNSの詳細
- DHCPとARP
- HTTPの進化
- HTTP/1.1の詳細
- HTTP/2の詳細
- HTTP/3とQUIC
- TLSの詳細
- WebSocketとServer-Sent Events
- ネットワークセキュリティの基礎
- プロキシと逆プロキシ
- CDNと負荷分散
- ファイアウォールとVPN
- ネットワーク仮想化
- ゲートウェイ冗長化とリンク冗長化
- ネットワーク運用の基礎
- ネットワーク観測とトラブルシューティング
- HTTP/2 と HTTP/3
- 性能チューニングと最適化
- 現在の動向
- 補足
- まとめ
- 参考文献
概要
DNS・TCP・TLS・HTTPを一本の流れで理解する
Web、API、動画配信、チャット。現代のシステムはほとんどネットワークの上で動いています。ネットワークを層に分けて理解し、実際のWeb通信がどのように成立するかを追います。
ネットワークを理解するコツは、層、名前解決、転送、暗号化、アプリケーション意味論を分けて考えることです。本テキストでは、ARPANETからHTTP/3とQUICまでの歴史的進化、各層の詳細な動作機構、実装戦略、そして2025-2026年の最新動向を網羅します。
この章で重視すること
- DNS、TCP、TLS、HTTPを別々の単語で終わらせず、1本の通信として追う
- トラブル時に「どの層が怪しいか」を切り分ける
- HTTP/2やHTTP/3の"何が変わったのか"を意味と運び方の違いで捉える
- TCPの輻輳制御の進化(Reno → CUBIC → BBR → BBRv3)を実務的に理解する
- DNS、TLSの詳細仕様と実装トレードオフを深掘りする
- CDN、ロードバランサ、ファイアウォール、VPNなどの実装戦略を一通り扱う
ネットワークの歴史
ネットワーク技術の進化を理解すると、なぜ今の設計になっているのかが見えやすくなります。
ARPANETからTCP/IPへ
1969年、アメリカ国防総省のARPA(Advanced Research Projects Agency)が資金を出し、複数の大学をつなぐ実験的ネットワークARPANETが誕生しました。
-
初期(1960-70s): ARPANETでは、メッセージが複数のパケットに分割され、ルータ経由で目的地に届けられるという考え方が確立されました。これは、中央の交換機に依存する電話網と異なり、障害時の耐性が高い設計です。
-
TCP/IPの登場(1983): 1983年、ARPANETは標準通信プロトコルとしてTCP/IPを採用しました。これは、異なるネットワーク同士を相互接続するための統一された仕組みを提供しました。
コード例は、そのまま写すためだけのものではありません。直前の本文で「何を確かめる例か」を押さえ、直後の説明で「どの性質が見えるか」を確認してください。実務では、ここに入力の境界、失敗時の挙動、依存する実行環境を足して読むと判断しやすくなります。
World Wide WebとHTTP/0.9
1989年、CERNのTim Berners-Leeが、情報共有システムとしてWorld Wide Webを発明しました。HTTP/0.9は極めてシンプルで、GETメソッドのみ、レスポンスはテキストのみ、という特徴がありました。
GET /page.html\r\n
\r\n
レスポンスはHTMLをそのまま返すだけでした。ステータスコード、ヘッダ、メタデータという概念は存在しませんでした。
HTTP/1.0と メタデータの導入
HTTP/1.0(1996)では、リクエスト・レスポンスの構造が確立されました。
GET /page.html HTTP/1.0
Host: example.com
User-Agent: Mozilla/1.0
レスポンスは以下のように構造化されました:
HTTP/1.0 200 OK
Content-Type: text/html
Content-Length: 1234
<html>...</html>
ステータスコード、ヘッダフィールドが導入され、複数の型をサポートできるようになりました。ただし接続は1リクエストごとに切断される(コネクションレス)という特徴がありました。
HTTP/1.1と 持続接続
HTTP/1.1(1997・1999)では、デフォルトで1本のTCP接続を複数リクエストで再利用する「持続接続」(Keep-Alive)が標準化されました。これにより、接続確立のオーバーヘッドが大幅に削減されました。
GET /page1.html HTTP/1.1
Host: example.com
Connection: keep-alive
(接続は再利用)
GET /page2.html HTTP/1.1
Host: example.com
(接続を閉じる)
同時に、キャッシュ制御(Cache-Control、ETag)、チャンク転送(Transfer-Encoding: chunked)、条件付きGET(If-Modified-Since)などの機能が追加されました。
層に分ける理由
ネットワークは複雑なので、役割ごとに層に分けます。
これにより、「どこが怪しいか」を切り分けやすくなります。
なぜ層が必要なのか
層の考え方は、ネットワークだけの特殊事情ではありません。複雑な仕組みを
のように分けることで、変更に強くし、責任範囲を明確にします。
たとえばHTTPを理解したいからといって、毎回ルータの実装まで意識する必要はありません。逆にTCPの再送を考えるとき、HTTPのステータスコードは脇へ置けます。層とは、考える単位を分ける技法 です。
OSI参照モデルとTCP/IPの対応
ネットワークの層構造を理解するには、OSI参照モデルと実際のTCP/IPスタックの関係を把握することが重要です。
| 層 | OSI名称 | 主な機能 | TCP/IPでの対応 |
|---|---|---|---|
| 7 | アプリケーション | ユーザ向けサービス | HTTP, SMTP, DNS, SSH |
| 6 | プレゼンテーション | データ表現変換 | TLS, gzip |
| 5 | セッション | セッション管理 | HTTPステートレス + Cookie |
| 4 | トランスポート | エンドツーエンド転送 | TCP, UDP, QUIC |
| 3 | ネットワーク | ルーティング | IPv4, IPv6, ICMP |
| 2 | データリンク | フレーム送受信 | Ethernet, Wi-Fi, PPP |
| 1 | 物理 | 物理伝送 | 光ファイバ、銅線、電波 |
実務ではTCP/IPモデル(4層)のほうが使われることが多いです:
- アプリケーション層(5-7層をまとめる)
- トランスポート層(4層)
- インターネット層(3層)
- リンク層(2-1層をまとめる)
物理層とリンク層
物理層の進化
データを電気信号として物理的に送受信する層です。
銅線(イーサネット)
10Base-T(10 Mbps、CAT3)→ 100Base-TX(100 Mbps、CAT5)
→ 1000Base-T(1 Gbps、CAT5e)→ 10GBase-T(10 Gbps、CAT6A)
RJ-45コネクタで接続され、距離は通常100mが目安です。
光ファイバ
シングルモード(遠距離・高速)→ 100km以上
マルチモード(短距離・低コスト)→ 2km程度
データセンタ間の長距離リンクには光ファイバが使われます。現在、400 Gbpsリンクも実装されつつあります。
無線(Wi-Fi・5G・衛星)
Wi-Fiの進化:
802.11a/b/g(<54 Mbps)
→ 802.11n(Wi-Fi 4, 600 Mbps)
→ 802.11ac(Wi-Fi 5, 3.5 Gbps)
→ 802.11ax(Wi-Fi 6, 10 Gbps)
→ 802.11be(Wi-Fi 7, 46 Gbps)
5G・衛星:
- 5G: 下り最大10 Gbps、遅延1-10ms
- 6G研究中(2030年代想定)
- Starlinkなどの衛星通信:遅延20-40ms、カバレッジが広い
リンク層(データリンク層)
Ethernetフレーム構造
MACアドレスは48ビット(6オクテット)で、通常は 00:1A:2B:3C:4D:5E の形式です。
VLAN(仮想LAN)
物理的には1本のケーブルでも、論理的に複数のLANに分割できます。
VLANは802.1Qタグで実装され、フレームに4Bのタグ情報を挿入します。異なるVLANは直接通信できず、L3スイッチやルータでルーティングが必要です。
Spanning Tree Protocol(STP)
複数のスイッチが接続されたときにループが生じるのを防ぎます。ツリー構造を動的に計算し、一部のリンクをブロック状態にします。
ネットワーク層(IPv4・IPv6)
IPv4の構造
IPアドレスは32ビット(4オクテット)で表現されます。
CIDR(クラスレス・ドメイン・ルーティング)
CIDR記法 192.0.2.0/24 は、最初の24ビットがネットワークを表します。
192.0.2.0/24 → ネットワーク: 192.0.2.0
ブロードキャスト: 192.0.2.255
ホスト数: 254(.0と .255は予約)
サブネットマスク 255.255.255.0 と同じ意味です。
プライベートアドレス(RFC 1918)
10.0.0.0/8 → 10.0.0.0 ~ 10.255.255.255(1677万個)
172.16.0.0/12 → 172.16.0.0 ~ 172.31.255.255(104万個)
192.168.0.0/16 → 192.168.0.0 ~ 192.168.255.255(65000個)
これらはインターネット上にはルーティングされず、社内ネットワークで自由に使用できます。
IPv6の構造
IPv6は128ビット(16オクテット)で、 2^128個(約340兆の兆倍)のアドレスを提供します。
2001:0db8:85a3:0000:0000:8a2e:0370:7334
短縮記法:
2001:db8:85a3::8a2e:370:7334
連続するゼロは :: で1回だけ省略できます。
IPv6アドレスの種類
| タイプ | プレフィックス | 用途 |
|---|---|---|
| ユニキャスト | 2000::/3 | 通常のアドレス |
| リンク・ローカル | fe80::/10 | リンク内通信(自動設定) |
| マルチキャスト | ff00::/8 | 1対多通信 |
| ループバック | ::1/128 | 自ホスト(IPv4の127.0.0.1) |
IPv6の利点
ICMP(Internet Control Message Protocol)
IPネットワークの診断・制御に使われます。
ping(echo request/reply)
→ ネットワーク到達性確認
traceroute(TTLを段階的に増やし、各ルータの応答を観察)
→ ルート経路の確認
IPv6のNDP(Neighbor Discovery Protocol)
IPv6ではARPの代わりにNDPが使われます。
- Router Advertisement(RA): ルータが定期的に自身の情報を送信
- Neighbor Solicitation(NS): 「このアドレスは誰か」と問い合わせ(ARPに相当)
ルーティングプロトコル
スタティック・ルーティング
ルータの管理者が手動で経路を設定します。
route add 192.168.1.0/24 via 10.0.0.1
小規模ネットワークでは十分ですが、大規模・複雑なネットワークではスケールしません。
ダイナミック・ルーティング
ルータ同士が自動的に経路情報を交換し、最適な道を見つけます。
RIP(Routing Information Protocol)
最古のダイナミック・ルーティングプロトコル。ホップ数(リンク数)を基準に経路を選択。ただしホップ上限15と制限が厳しく、現代ではほぼ使われません。
OSPF(Open Shortest Path First)
リンク状態型プロトコル。各ルータが全ネットワークの位相図を持ち、Dijkstraアルゴリズムで最短経路を計算します。
利点:
- スケーラビリティ(数千ホップ以上対応)
- 収束が高速
- エリア分割で管理性向上
欠点:
- 計算コスト大
- 設定が複雑
BGP(Border Gateway Protocol)
自律システム(AS)間のルーティングに使われます。インターネットの主要なルーティングプロトコルです。
AS1 AS2 AS3
↔ BGP ↔ ↔ BGP ↔
BGPは経路長(ホップ数)だけでなく、ポリシー(経由したくない、優先する)をルーティング決定に含めます。
MPLS(Multiprotocol Label Switching)
IPの前に短いラベルを付加し、ラベル交換でパケットを高速に転送します。QoSやTE(トラフィックエンジニアリング)に用いられます。
IPヘッダ | MPLSラベル | ペイロード
パケットとルーティング
データは巨大な塊のままではなく、パケットに分けて送られます。
- 分割: 大きなデータを小さなパケットに分割
- 再送: 失われたパケットだけを再送
- 経路選択: 個々のパケットが異なる経路を取ることもある
ルータは「次の一歩」を決めながらパケットを目的地へ運びます。
ルーティングテーブルと最長一致
ルータは受信パケットの宛先IPを見て、ルーティングテーブルから「次はどこへ」を決定します。複数のエントリがマッチする場合、最長マスク一致(Longest Prefix Match)が優先されます。
ルーティングテーブル例:
宛先 ネクストホップ
192.168.1.0/24 eth0
192.168.0.0/16 eth1
0.0.0.0/0 10.0.0.1(デフォルトゲートウェイ)
宛先が 192.168.1.5 の場合、192.168.1.0/24 にマッチしeth0へ送出;192.168.2.5 の場合、192.168.0.0/16 にマッチしeth1へ送出されます。
端から端まで一直線ではない
インターネット通信は、専用線のように固定の道をそのまま流れるとは限りません。途中には複数のルータ、ISP、データセンタ、CDNなどがあり、その時々の経路選択や障害状況によって通り道が変わることがあります。
このため、
- あるときだけ遅い
- 一部地域だけつながらない
- 片方向だけおかしい
といった現象が起こりえます。
TTLと「どこまで進んだか」
各パケットは TTL(Time To Live) という8ビットのカウンタを持ちます。ルータを通過するたびに1減少し、0になるとパケットは廃棄されます。これにより、無限ループを防ぎます。
初期TTL = 64(Linux)や128(Windows)
ルータ1通過後:63
ルータ2通過後:62
...
TTL = 0になったら廃棄
traceroute はこのTTLを段階的に増やし、各ステップでICMP Time Exceededを集めることで、経路を観察します。
$ traceroute example.com
1 192.168.1.1 (192.168.1.1) 1.234 ms
2 203.0.113.1 (203.0.113.1) 5.678 ms
3 198.51.100.1 (198.51.100.1) 12.345 ms
...
トランスポート層の概観
トランスポート層は、エンドツーエンドの通信チャネルを提供し、ポート番号によって複数のアプリケーションを多重化します。
ポート番号の役割
同一IPでも異なるポートに複数のサービスが動作する場合がありますが、これはトランスポート層が実現しています。
TCPとUDP
| 特性 | TCP | UDP |
|---|---|---|
| 信頼性 | ○(再送) | ×(ベストエフォート) |
| 順序保証 | ○ | × |
| コネクション | ○(3-way handshake) | × |
| オーバーヘッド | 中程度 | 低い |
| 用途 | HTTP, SMTP, SSH | DNS, VoIP, ゲーム, QUIC |
TCPの詳細
TCPの3者ハンドシェイク(3-Way Handshake)
TCPはいきなり本編を送り始めるのではなく、接続の準備をします。
-
クライアント → サーバ:
SYN(シーケンス番号 = 100)- クライアントが「接続したい」とシグナルを送信
- クライアント側の状態:
-
サーバ → クライアント:
SYN-ACK(シーケンス番号 = 300、確認番号 = 101)- サーバが「わかった、こちらも準備できた」と応答
- サーバ側の状態:
-
クライアント → サーバ:
ACK(シーケンス番号 = 101、確認番号 = 301)- クライアントが受信を確認し、接続確立
- 両側の状態:
ESTABLISHED
この3ステップはネットワークの遅延を勘案しており、双方が確実に「接続準備できた」ことを確認します。
なぜ3ステップ必要か
2ステップだと、サーバがクライアントの最初のSYNを確認できません。仮にSYN-ACKが返されたとしても、サーバ側は「本当にクライアントがそれを受け取ったか」が不明です。3ステップ目のACKでこれが確認されます。
シーケンス番号と確認番号
TCPは各バイトに番号を付けることで、順序性と信頼性を実現します。
クライアント → サーバ
バイト1-100:seq=1000, ack=2000(サーバからのseq=2000を受け取ったことを示す)
バイト101-200:seq=1100, ack=2000
サーバ → クライアント
バイト1-50:seq=2000, ack=1001(クライアントのバイト1-100を受け取ったことを示す)
TCPの状態遷移
TCPコネクションには複数の状態があります。
フロー制御(Flow Control)
相手の受け皿の大きさに合わせて、送信量を調整します。
スライディングウィンドウ
TCP受信側は RWND(Receive Window)という値を送信側へ通知し、「この量までなら受け取れる」と伝えます。
送信側の送信可能な区間:
次送信シーケンス番号:100
確認済みシーケンス番号:50
RWND = 1000
送信可能な範囲:50 + 1000 = 1050まで
受信側のバッファが詰まるとRWNDが小さくなり、送信側は送信速度を落とします。
輻輳制御(Congestion Control)
ネットワーク全体の混雑に合わせて、送信量を調整します。
TCP Slow Start(スロースタート)
新規接続や再送後は、段階的に送信量を増やしていきます。
初期CWND(Congestion Window)= 1 MSS
ラウンドトリップタイム(RTT)ごとに倍増:
1 → 2 → 4 → 8 → 16 → ...
しきい値(SSTHRESH)に達したら線形増加に移行
TCP Reno
長らく標準だったアルゴリズム。パケット損失時はCWNDを半減し、その後線形に増加。
CWND = 16 MSS時にパケット損失
↓
CWND = 8 MSSに低下
↓
8 → 9 → 10 → 11 ... と線形増加
TCP CUBIC
Linux 3.2以降のデフォルト。数学的に計算された3次曲線を使い、ネットワーク遡及時間(RTT)の違いに自動適応します。
CWND = C * (t - K)^3 + W_max
C:スケーリング定数
t:時間
K:回復点
W_max:直前のパケット損失時の最大CWND
CUBICは異なるRTTのフロー間で比較的公平に頻域を共有します。
TCP BBR(Bottleneck Bandwidth and RTT)
Googleが開発した革新的なアルゴリズム。パケット損失ではなく、到達可能な帯域幅と往復遅延を測定し、それに基づいてCWNDを決定します。
パケット到着率の測定 → 推定帯域幅
RTT測定 → 推定遅延
CWND = 推定帯域幅 × RTT
利点:
- パケット損失がない環境でも効率的に帯域を使用
- バッファ充満(bufferbloat)を軽減
- 衛星通信など遅延が大きい環境で有効
TCP BBRv3(2024年登場)
BBRの改良版。複数フロー間の公平性向上と、初期化フェーズの改善。
Nagleアルゴリズム
小さなパケットが多数送信されるのを防ぐため、確認されていないデータがあれば、次のデータを待ってまとめて送信します。これは遅延を増加させるため、リアルタイム性が重要なアプリ(SSH、オンラインゲーム)では無効化(TCP_NODELAY)されることが多い。
Karnのアルゴリズム
再送されたパケットへの応答を、RTT測定に含めません。そうしないと、本当のRTTが分からなくなるからです。
Fast RetransmitとFast Recovery
3つの重複したACKを受け取ったら、タイムアウト待たずに即座に再送します。
正常系:
データ1, 2, 3, 4, 5送信
ACK 1, ACK 2, ACK 3(正常)
異常系:
データ1, 2, 3, 4, 5送信
ACK 1, ACK 2, ACK 2, ACK 2(データ3が欠損)
→ 3つの重複ACKで即座にデータ3を再送
UDPの詳細
UDPは「最小限の輸送層」です。信頼性制御をアプリに委ねることで、低遅延・低オーバーヘッドを実現します。
UDPヘッダ
わずか8バイトです。TCPのヘッダ(最小20バイト)と比べ、オーバーヘッドが小さい。
UDPの用途
DNS(Domain Name System)
ほぼすべてのDNSクエリがUDP port 53を使用(大規模レスポンスはTCPにフォールバック)。要求・応答が1往復で済み、遅延が重要だからです。
クライアント → DNSサーバ(UDP port 53)
↓
サーバが即座に応答
↓
クライアント受信
VoIP(Voice over IP)
遅延が重要。一部のパケット損失は音声品質低下で許容可能。
オンラインゲーム
低遅延が命。プレイヤー位置の同期などはUDPで行い、クリティカルなデータ(クエストの進行など)はTCPで確認するハイブリッドアプローチもあります。
HTTP/3とQUIC
HTTP/3はUDP上のQUICで動作します。QUIC自体がUDP上に信頼性制御を実装しており、事実上、アプリケーション層でTCPのような機能を実現しています。
ソケットプログラミング
アプリケーションがネットワークを使うとき、多くの場合はソケットAPIを通ります。ソケットは「ネットワーク通信のためのファイル記述子のような窓口」と考えるとわかりやすいです。
BSDソケットAPI
UNIX / Linuxの標準ソケットAPI。
TCPサーバの基本形
// Node.jsの例
const net = require('net');
const server = net.createServer((socket) => {
socket.on('data', (data) => {
console.log('受信:', data.toString());
socket.write('エコー: ' + data);
});
socket.on('end', () => {
console.log('接続終了');
});
});
server.listen(3000, '127.0.0.1');
TCPクライアント
const net = require('net');
const socket = net.createConnection(3000, '127.0.0.1', () => {
socket.write('Hello Server');
});
socket.on('data', (data) => {
console.log('レスポンス:', data.toString());
});
ソケットのI/Oモデル
ブロッキングI/O
// socket.read() は データが来るまで待機
const data = socket.read();
シンプルですが、複数クライアントを扱う場合は各クライアント分のスレッドが必要になり、スケールしません。
ノンブロッキングI/O
// データがなければすぐにnullを返す
const data = socket.read();
if (data === null) {
// データがない
}
複数クライアントを1スレッドで処理できますが、ポーリングが必要です。
マルチプレクシング
複数のソケットの状態を効率的に監視します。
select(古い、ポータブル):
fd_set readfds;
FD_SET(socket_fd, &readfds);
select(max_fd + 1, &readfds, NULL, NULL, &timeout);
if (FD_ISSET(socket_fd, &readfds)) {
// このソケットにデータが来た
}
制限:監視できるソケット数がOSの上限(通常1024)。
poll(selectより良い):
struct pollfd fds[100];
fds[0].fd = socket_fd;
fds[0].events = POLLIN;
poll(fds, 100, timeout);
selectより制限が緩い(ただしO(n) の線形走査)。
epoll(Linux、高速):
int epfd = epoll_create1(0);
struct epoll_event event;
event.events = EPOLLIN;
event.data.fd = socket_fd;
epoll_ctl(epfd, EPOLL_CTL_ADD, socket_fd, &event);
struct epoll_event events[100];
int nready = epoll_wait(epfd, events, 100, timeout);
epollはカーネルが内部的にレディー状態のソケットを追跡し、O(k) でk個のレディーソケットを返します(kは少数)。Linuxサーバアプリケーションの標準です。
kqueue(BSD / macOS):
int kq = kqueue();
struct kevent kev;
EV_SET(&kev, socket_fd, EVFILT_READ, EV_ADD, 0, 0, NULL);
kevent(kq, &kev, 1, NULL, 0, NULL);
struct kevent events[100];
int nready = kevent(kq, NULL, 0, events, 100, &timeout);
BSD/macOSの高効率なマルチプレクシング。
io_uring(Linux 5.1+、最新):
従来のシステムコール(epoll_waitなど)をキューイングし、バッチ処理することで、システムコールのオーバーヘッドを大幅に削減。
struct io_uring ring;
io_uring_queue_init(QUEUE_DEPTH, &ring, 0);
struct io_uring_sqe *sqe = io_uring_get_sqe(&ring);
io_uring_prep_read(sqe, fd, buf, BUF_SIZE, 0);
io_uring_submit(&ring);
struct io_uring_cqe *cqe;
io_uring_wait_cqe(&ring, &cqe);
// 完了情報を処理
バッファとTCP Nagleアルゴリズム
送信バッファ
socket.write('Hello'); // すぐには送信されず、バッファに溜まる
socket.write(' World'); // まとめて送信されるかもしれない
TCP_NODELAYオプションでNagleアルゴリズムを無効化し、即座に送信。
socket.setNoDelay(true); // TCP_NODELAYを有効
受信バッファ
socket.on('data', (chunk) => {
// chunkはアプリケーションで決定した単位ではなく、
// TCPが区切った単位(通常1-64 KB)
});
アプリケーションは「1 read = 1 write」を仮定できません。複数のパケットがまとめて来たり、1つのパケットが複数のreadに分かれることもあります。
DNSの詳細
DNS階層構造
DNSは分散データベースであり、単一の電話帳ではありません。
DNSクエリ方式
再帰クエリ(Recursive Query)
「この名前を解いてくれ」とリゾルバに問い合わせ。リゾルバが全責任で回答を返す。
クライアント: "www.example.comのアドレスは?"
リゾルバ: "192.0.2.1です"
反復クエリ(Iterative Query)
「この名前のサーバはどこ?」と問い合わせ。相手は「ここなら知ってるよ」という示唆を返す。
クライアント: "www.example.comはどこ?"
ルート: "TLDサーバがいるよ → 198.51.100.1"
クライアント: "198.51.100.1へ、www.example.comはどこ?"
TLD: "権威サーバがいるよ → 203.0.113.1"
DNSレコードタイプ
| タイプ | 用途 | 例 |
|---|---|---|
| A | IPv4アドレス | www.example.com → 192.0.2.1 |
| AAAA | IPv6アドレス | www.example.com → 2001:db8::1 |
| MX | メールサーバ | example.com → mail.example.com |
| CNAME | 別名 | www.example.com → example.com |
| NS | ネームサーバ | example.com → ns1.example.com |
| TXT | テキスト・その他 | SPF・DKIM検証など |
| SOA | ゾーン情報 | シリアル番号・TTLなど |
| SRV | サービス位置 | _sip._tcp.example.com |
DNSキャッシュとTTL
リゾルバがwww.example.comを解き、Aレコード(TTL: 3600)を取得
→ 3600秒間、ローカルキャッシュに保持
→ 次の同一クエリはキャッシュから即座に返却
→ 3600秒経過後、再度権威サーバへ問い合わせ
TTLが短いと(60秒など)、キャッシュ効果が低く問い合わせが頻繁。長いと(86400秒 = 1日など)、変更反映が遅い。
DNSSEC(DNS Security Extensions)
DNSへの中間者攻撃(DNSポイズニング、キャッシュ汚染)を防ぐため、デジタル署名を使用。
権威サーバがDNSKEY(公開鍵)とRRSIG(署名)を返却
→ リゾルバが署名を検証
→ 改ざんされたレスポンスを検出可能
チェーン検証:子ゾーン(example.com)のDNSKEYは、親ゾーン(.com)のDSレコードで署名される。これにより信頼の連鎖が確立されます。
DoT(DNS over TLS)とDoH(DNS over HTTPS)
通常のDNSは平文で送受信されるため、盗聴・改ざんが可能。
DoT:DNS over TLS
DNSクエリをTLSで暗号化。
クライアント --TLS→ DNSサーバ(port 853)
↓
DNSクエリがTLSで保護される
DoH:DNS over HTTPS
DNSクエリをHTTPS(HTTP/2やHTTP/3)で送信。
POST https://dns.example.com/dns-query?dns=... HTTP/1.1
(base64エンコードされたDNSメッセージ)
DoHはネットワーク監視ツール(企業ファイアウォール)による検査が難しいため、プライバシーはより強い一方で、組織のポリシー執行が難しくなるという議論もあります。
DoQ(DNS over QUIC)
QUICを使い、0-RTTでの問い合わせが可能。HTTP/3対応のインフラが整うにつれて普及予定。
DHCPとARP
DHCP(Dynamic Host Configuration Protocol)
ネットワーク接続時に、IPアドレスを自動割り当て。
DHCPリース:IPは一時的な貸与。期間(デフォルト24-48時間)を過ぎると返却。ホストは期間中盤で更新要求(DHCP RENEW)。
ARP(Address Resolution Protocol)
IPアドレスからMACアドレスを解く。
「192.168.1.1のMACアドレスは?」というブロードキャスト
→ 192.168.1.1を持つホストが応答
→ MACアドレスを習得
同一LAN内(同一サブネット)の通信では、ARPで相手のMACアドレスを習得してからEthernetフレームを送信します。
ARPスプーフィング攻撃:異なるホストが「私が192.168.1.1です」と偽るARP Replyを送り、トラフィックをリダイレクト。対策:ARPテーブルの検証、VLAN分離など。
HTTPの進化
HTTP/0.9
GET /index.html\r\n
\r\n
返却:
<HTML>
...
</HTML>
メソッドはGETのみ、ヘッダなし、ステータスコードなし。
HTTP/1.0
GET /index.html HTTP/1.0\r\n
Host: www.example.com\r\n
User-Agent: Mozilla/1.0\r\n
\r\n
レスポンス:
HTTP/1.0 200 OK\r\n
Content-Type: text/html\r\n
Content-Length: 1234\r\n
Connection: close\r\n
\r\n
<HTML>...</HTML>
- ステータスコード導入
- ヘッダフィールド導入
- コネクション毎に1リクエスト(接続オーバーヘッド大)
HTTP/1.1
GET /index.html HTTP/1.1\r\n
Host: www.example.com\r\n
Connection: keep-alive\r\n
\r\n
同一接続で複数リクエスト可能(Keep-Alive)。
GET /image1.png HTTP/1.1\r\n
Host: www.example.com\r\n
\r\n
(接続を再利用)
GET /image2.png HTTP/1.1\r\n
Host: www.example.com\r\n
\r\n
HTTP/1.1の主な機能
- キャッシュ制御:
,
ETag,Last-Modified - チャンク転送:
Transfer-Encoding: chunked(コンテンツサイズ未知のときに有用) - 範囲リクエスト: (動画・大容量ファイルの部分取得)
- 条件付きGET:
If-Modified-Since,If-None-Match(キャッシュ検証)
HTTP/1.1の課題
Head-of-Line Blocking (HoL):
request 1送信 → response 1受信待ち
request 2送信 → response 1が来るまで待機(応答が遅いとHoL)
request 3送信 → request 2と同様に待機
1本の接続で複数リクエストを順番に処理するため、前のレスポンス待ちで後ろが止まります。
HTTP/1.1の詳細
HTTPメソッド
| メソッド | 用途 | 冪等性 |
|---|---|---|
| GET | リソース取得 | ○ |
| POST | データ送信・新規作成 | × |
| PUT | リソース更新(全置換) | ○ |
| DELETE | リソース削除 | ○ |
| PATCH | リソース部分更新 | × |
| HEAD | GETと同じ(本体なし) | ○ |
| OPTIONS | 利用可能メソッド確認 | ○ |
冪等性:同じリクエストを複数回実行しても同じ結果が得られること。GET・PUT・DELETEは冪等;POST・PATCHは非冪等(重複実行で重複副作用)。
ステータスコード
| 範囲 | 分類 | 例 |
|---|---|---|
| 1xx | 情報応答 | 100 Continue |
| 2xx | 成功 | 200 OK, 201 Created, 204 No Content |
| 3xx | リダイレクト | 301 Moved Permanently, 302 Found, 304 Not Modified |
| 4xx | クライアントエラー | 400 Bad Request, 401 Unauthorized, 403 Forbidden, 404 Not Found |
| 5xx | サーバエラー | 500 Internal Server Error, 503 Service Unavailable |
HTTPヘッダ
リクエストヘッダ
Host: 要求先ホスト(必須)User-Agent: クライアント識別Accept: クライアントが受け付けるコンテンツタイプAccept-Language: 言語Cookie: セッション・トラッキング情報Authorization: 認証情報Content-Type: 本体のデータ形式Content-Length: 本体サイズ
レスポンスヘッダ
Server: サーバ識別(Apache、nginxなど)Content-Type: 本体のデータ形式Content-Length: 本体サイズCache-Control: キャッシュ指示ETag: 一意なバージョン識別子Last-Modified: 最終更新日時Set-Cookie: クライアント側にcookieを保存Location: リダイレクト先URLStrict-Transport-Security: HTTPS強制
キャッシュ戦略
Cache-Control: max-age=3600
→ 3600秒はキャッシュを使用、サーバ問い合わせなし
Cache-Control: no-cache
→ キャッシュ使用前に条件付きGET(If-None-Match)でサーバ確認
Cache-Control: no-store
→ キャッシュするな(機密情報など)
CookieとSession
レスポンス:
Set-Cookie: session_id=abc123; Path=/; HttpOnly; Secure; SameSite=Strict
クライアント保存:
Cookie: session_id=abc123
次のリクエスト:
GET /page HTTP/1.1
Host: example.com
Cookie: session_id=abc123
HttpOnly: JavaScriptからaccess不可(XSS対策)Secure: HTTPSのみ送信SameSite: CSRF対策(Strict / Lax / None)
Content Negotiation(コンテンツ交渉)
クライアントが Accept ヘッダで希望形式を示し、サーバが最適なバージョンを返す。
GET /api/user HTTP/1.1
Accept: application/json, application/xml;q=0.9
(application/jsonが優先度高い)
サーバはJSONを返す可能性が高い。qパラメータで優先度を指定。
HTTP/2の詳細
HTTP/1.1のHead-of-Line Blockingを解決するため、HTTP/2は複数のリクエスト・レスポンスを1本のTCP接続で多重化します。
バイナリフレーミング
HTTP/1.1はテキスト(改行区切り)。HTTP/2は固定長フレーム。
バイナリ形式により、高速パース・効率的なフレーミングが可能。
ストリーム
HTTP/2では、1本のTCP接続内に複数の「ストリーム」があり、各ストリーム内でリクエスト・レスポンスのペアが独立して動作。
ストリームIDは奇数(クライアント発信)と偶数(サーバ発信)で区別。
多重化のメリット:
- Head-of-Line Blocking回避(1リクエスト遅延が他に影響しない)
- 接続確立オーバーヘッド削減
- TCPウィンドウ共有(効率的な帯域利用)
HPACK(圧縮ヘッダ)
HTTP/1.1では各リクエストで同一ヘッダが繰り返されるため、無駄が多い。
GET /page1.html HTTP/1.1
Host: example.com
User-Agent: Mozilla/5.0
Accept: */*
GET /page2.html HTTP/1.1
Host: example.com
User-Agent: Mozilla/5.0
Accept: */*
(User-AgentとAcceptが重複)
HPACKは動的テーブルを使い、既出のヘッダを参照インデックスで送信。
フレーム1:
HEADERS + Literal(User-Agent: Mozilla/5.0)→ テーブルに記録、インデックス62に登録
フレーム2:
HEADERS + インデックス62(ユーザーエージェントは前と同じ)
圧縮率は通常30~50%。
優先度付けとリソースヒント
ストリーム同士で優先度を指定可能。
サーバはこの優先度に基づき、帯域割り当てを最適化。
Server Push
サーバが「このリソースはいるだろう」と推測し、クライアントの要求なしに送信。
クライアント:
GET /page.html
サーバ(PUSH_PROMISEフレーム):
「/page.htmlに関連する /style.cssと /script.jsも送るね」
(その後、DATAフレームで3リソース全て送信)
ただし誤ったプッシュはネットワーク浪費につながるため、慎重な使用が必要。
HTTP/3とQUIC
HTTP/3は、QUICというプロトコル(UDP上でTCP並みの信頼性を実装)上で動作。従来のTCPベースではなく、UDPベースで多くの改善を実現。
QUICの特徴
接続確立の高速化
TCPでは3-way handshakeで1 RTT、TLS 1.2では1 RTT(合計2 RTT)必要。
TCP/TLS 1.2:
Client → Server: SYN
Server → Client: SYN-ACK
Client → Server: ACK, TLS ClientHello
Server → Client: TLS ServerHello, ...
(データ送信は2 RTT後)
QUICでは初回接続も1 RTTで済みます。さらに0-RTT(resumption tokenにより初期化パラメータを再利用)を使えば、接続直後にデータ送信可能。
QUIC 0-RTT:
Client → Server: Initial + Handshake + データ(1パケット)
Server → Client: レスポンス
(即座に通信開始)
コネクションマイグレーション
TCPはIP・ポートペア(5-tuple)で識別するため、ネットワーク変更(WiFi → LTE)でコネクション喪失。
QUICはConnection IDを使い、IP変更後も同一接続を継続。
初期接続:192.168.1.10 (WiFi)
↓(WiFi圏外になりLTEに切り替わり)
↓ IPが203.0.113.5に変更
→ QUICはConnection IDで同一接続と認識、継続
モバイル環境で大幅な改善。
多重化の改善
HTTP/2はTCP上で多重化するため、1パケット損失が全ストリームに影響(Head-of-Line Blocking)。
TCPのコンテキスト:
パケットA(Stream 1のDATA)
パケットB(Stream 2のDATA)
パケットC(Stream 3のDATA)
パケットB喪失 → 再送待ちの間、Stream 2停止
(Stream 1・3は続行)
ただしTCPのバッファ・セグメント化により、局所化される
QUICではパケット損失がそのストリームのみに限定。
QUICのコンテキスト:
フレームA(Stream 1のDATA)
フレームB(Stream 2のDATA)
フレームC(Stream 3のDATA)
フレームB喪失 → Stream 2だけ再送
Stream 1・3は影響なし(QUICレベルでの独立性)
組み込み暗号化
QUICはハンドシェイクから暗号化。盗聴・改ざんへの耐性が高い。
TCP/TLS 1.2:
SYN(平文)
SYN-ACK(平文)
ClientHello(TLSハンドシェイク初期、部分的に平文)
QUIC:
Initial Packet(全てHandshake Keyで暗号化)
HTTP/3フレーム
HTTP/2と基本構造は共通ですが、QUICフレーム上に多重化。
HTTP/3の実装状況
2024年時点:
- Chrome・Firefoxなどのモダンブラウザ:対応済み
- AWS・Google・CloudFlareなど主要CDN:対応済み
- 一部エンタープライズネットワーク:QUICポートブロック(port 80・443のみ許可など)
ブロックチェーンやゲーム、ビデオストリーミングで急速に採用が進行中。
TLSの詳細
TLS 1.2とTLS 1.3の比較
TLS 1.2ハンドシェイク(1.5 RTT)
TLS 1.2:
- ClientHello(クライアントの対応cipher suite・乱数を送信)
- ServerHello(サーバが選択したcipher suite・乱数、証明書、鍵交換パラメータを送信)
- ClientKeyExchange(クライアントが鍵交換完了)
- 双方でFinished(ハンドシェイク検証)
TLS 1.3ハンドシェイク(1 RTT)
TLS 1.3:
- ClientHelloに鍵交換パラメータを含める(1度のメッセージで共有鍵を計算可能)
- ServerHello受信直後にデータ送信可能
- 事実上1 RTTに短縮
0-RTT(Early Data)
TLS 1.3では、以前のハンドシェイク情報を再利用し、サーバへの接認証なしに初期データを送信可能(ただしリプレイ攻撃のリスクあり)。
セッション1:
Client → Server: ClientHello
Server → Client: ServerHello + session_ticket
セッション2(別日など):
Client → Server: ClientHello + session_ticket + Early Data(0-RTT)
(サーバがすぐにEarly Dataを処理開始)
Cipher Suite(暗号スイート)
TLSでは、以下の4要素の組み合わせを「Cipher Suite」と呼ぶ。
- 鍵交換(Key Exchange): RSA, ECDHE(楕円曲線Diffie-Hellman鍵交換), DHEなど
- 認証(Authentication): RSA, ECDSA, EdDSAなど
- 暗号化(Encryption): AES-128-GCM, AES-256-GCM, ChaCha20-Poly1305など
- メッセージ認証(MAC): SHA-256, SHA-384など
例:
- ECDHEで鍵交換
- RSAで認証
- AES-256-GCMで暗号化
- SHA-384で整合性確認
Forward Secrecy(前方秘匿性)
ECDHEなど「短命な」鍵を使うことで、長期秘密鍵(サーバの秘密鍵)が漏洩しても過去の通信は解読されない。
古い方式(RSA鍵交換):
過去に記録した通信
+ サーバ秘密鍵をハッキング取得
= 過去通信をすべて復号化可能(危険!)
新しい方式(ECDHE):
過去に記録した通信
+ サーバ秘密鍵をハッキング取得
= 過去通信は復号化不可(各セッションが独立鍵を使用)
証明書とPKI(Public Key Infrastructure)
X.509証明書
サーバが持つ公開鍵の正当性を確認するため、信頼される認証局(CA)が署名した証明書。
[ 証明書 ]
Subject: www.example.com
Issuer: Let's Encrypt Authority X3
Public Key: ... (RSA 2048)
Valid From: 2024-01-01
Valid To: 2025-01-01
Serial: 0x1234...
Signature: [SHA-256 with RSA]
ブラウザは証明書チェーンを検証:
www.example.com証明書
↓(署名検証用にParent CAの公開鍵を使用)
↓
Let's Encrypt Authority X3証明書
↓
Let's Encrypt Root CA証明書(ブラウザの信頼ストアに含まれる)
CAと信頼チェーン
複数のCAが階層をなす:
中間CAが漏洩してもルートCAは影響を受けない設計。
Let’s EncryptとACME(Automated Certificate Management Environment)
ACMEを使い、証明書の自動取得・更新・失効を実現。
1. サーバがLet's Encryptへ「www.example.comの証明書がほしい」と要求
2. Let's Encryptが「そのIPからアクセスできるか」を検証(DNS TXTレコード確認など)
3. 検証成功時、証明書を発行
4. サーバが設定・有効化
無料かつ90日有効期限が短く、自動更新前提の設計。
OCSP(Online Certificate Status Protocol)
証明書の失効状況をリアルタイム確認。
ブラウザ → OCSPレスポンダ:
「証明書SN=0x1234... はまだ有効?」
OCSPレスポンダ → ブラウザ:
「有効です(署名付き)」
ただしOCSPレスポンダへのアクセスが遅い場合があるため、OCSP Stapling(サーバが事前にOCSPレスポンスを取得しておき、TLSハンドシェイク時に一緒に送信)で改善。
WebSocketとServer-Sent Events
HTTPはRequest-Responseの同期モデル。リアルタイム双方向通信にはこれらの技術を使用。
WebSocket
HTTP upgradeメカニズムで、HTTPからWebSocketプロトコルへ昇格。
GET / HTTP/1.1
Host: example.com
Upgrade: websocket
Connection: Upgrade
Sec-WebSocket-Key: dGhlIHNhbXBsZSBub25jZQ==
Sec-WebSocket-Version: 13
サーバが受け入れると:
HTTP/1.1 101 Switching Protocols
Upgrade: websocket
Connection: Upgrade
Sec-WebSocket-Accept: s3pPLMBiTxaQ9kYGzzhZRbK+xOo=
以降、 TCP上で全二重通信(双方向同時)が可能。
WebSocketフレーム
FIN bit | RSV | opcode(TEXT/BINARY/CLOSE)| mask | payload length | payload
1 bit | 3 | 4 bits | 1 | 7-64 bits | variable
- TEXT(0x1): テキストデータ
- BINARY(0x2): バイナリデータ
- CLOSE(0x8): 接続閉鎖
- PING/PONG(0x9/0xA): keep-alive
WebSocketのメリット・デメリット
メリット:
- 低遅延の双方向通信
- チャット、リアルタイム通知に最適
デメリット:
- 中間プロキシ・ファイアウォール無視の可能性
- ステートフル(サーバ側の接続維持が必要)
Server-Sent Events(SSE)
サーバからクライアントへの一方向リアルタイム配信。HTTP上で実装可能。
GET /stream HTTP/1.1
Accept: text/event-stream
サーバが以下のように流送:
data: {"msg": "Hello"}\n
\n
retry: 5000\n
\n
event: notification\n
data: {"alert": "Warning"}\n
\n
クライアント(JavaScript):
const sse = new EventSource('/stream');
sse.addEventListener('notification', (e) => {
console.log(JSON.parse(e.data));
});
メリット:
デメリット:
- 一方向のみ(サーバ → クライアント)
ネットワークセキュリティの基礎
ネットワークレイヤーでの主要な脅威と対策。
ARP Spoofing(ARPなりすまし)
攻撃者が「私は192.168.1.1です(MAC: AA:BB:CC:DD:EE:FF)」と偽のARP Replyを送信。
ホストAが192.168.1.1へのトラフィックを攻撃者へ誤ります(中間者攻撃)。
正常なARP:
ホストA: 「192.168.1.1のMACは?」
ホストB: 「私です。MACはXX:XX:XX:XX:XX:XX」
攻撃:
ホストA: 「192.168.1.1のMACは?」
攻撃者: 「私です。MACはAA:BB:CC:DD:EE:FF」
ホストA: (騙される)
対策:
DNS Poisoning(DNS汚染)
正常:example.com → 192.0.2.1
攻撃後:example.com → 198.51.100.1(攻撃者のIP)
ユーザーがexample.comにアクセスするとフィッシングサイトへ。
対策:
- DNSSEC(署名検証)
- 信頼できるリゾルバ使用(8.8.8.8など)
- DoT / DoH
MITM(中間者攻撃)
攻撃者がクライアント・サーバ間の通信を傍受・改ざん。
クライアント ← 攻撃者 → サーバ
攻撃者:
- クライアント ↔ 攻撃者 間では攻撃者の証明書を提示(ブラウザ警告)
- 攻撃者 ↔ サーバ 間では正規の接続
対策:
- TLS(暗号化・認証)
- 証明書ピンニング(モバイルアプリ)
- HSTS(HTTP Strict-Transport-Security)
DDoS(Distributed Denial of Service)
複数の攻撃元からのトラフィック爆増でサービス停止。
ボットネット(感染コンピュータ群)
↓
同時多数のリクエスト
↓
サーバ過負荷orネットワーク飽和
種類:
対策:
- レート制限(Rate Limiting)
- DDoS対策サービス(Cloudflareなど)
- トラフィック分散(Anycast)
- BGPフィルタリング
TLSストリップ(SSL Stripping)
攻撃者がHTTPSをHTTPにダウングレード。
クライアント → 攻撃者(HTTPSをHTTPに変換)→ サーバ
サーバ → 攻撃者(HTTP) → クライアント(HTTPで見える)
対策:
- HSTS(ブラウザが自動的にHTTPS強制)
- Strict-Transport-Securityヘッダ
Strict-Transport-Security: max-age=31536000; includeSubDomains
プロキシと逆プロキシ
Forward Proxy(フォワードプロキシ)
クライアント側に置かれ、クライアントからの要求を代理。
クライアント → Proxy → インターネット
Proxyは:
- キャッシュ
- アクセス制御
- コンテンツフィルタリング
企業内ネットワークで、社員のインターネットアクセス監視・制限。
Reverse Proxy(リバースプロキシ)
サーバ側に置かれ、外部からのリクエストを内部サーバへ代理。
インターネット → Reverse Proxy → 内部サーバ
Proxyは:
- TLS終端
- キャッシュ
- 複数サーバへの振り分け(Load Balancing)
- 圧縮
実装例:nginx,Apache,HAProxy。
TLS終端
クライアント --HTTPS--> Reverse Proxy --HTTP--> 内部サーバ
(TLS) (平文)
リバースプロキシがTLSを終端することで、内部通信はシンプル化。ただしProxy内部通信は平文(信頼できるネットワーク内と仮定)。
キャッシュ
レスポンスをキャッシュし、同一リクエストは内部サーバへ接続せず返却。
リクエスト → Proxy(キャッシュにあり)→ すぐレスポンス
(以降も同一リクエストはキャッシュから)
キャッシュ無効化(Cache Invalidation):
- TTL経過
- サーバがキャッシュクリア指令
- クライアントが強制更新(Ctrl+Shift+R)
CDNと負荷分散
CDN(Content Delivery Network)
世界中に散在するエッジサーバで、利用者に近い場所からコンテンツを配信。
クライアント(東京)
↓ 直近のCDN POP(東京)から取得
↓
オリジン(us-west)へのアクセス削減
CDNの例
- Cloudflare: グローバルに200+ POP
- Akamai: 大規模・エンタープライズ向け
- AWS CloudFront: AWSインテグレーション
- Fastly: Varnishベース、高速エッジコンピューティング
キャッシュヒット率向上
Cache-Control: max-age=31536000, immutable
(1年キャッシュ、ファイル内容が変わらないことを保証)
バージョン付きURL:
/assets/app.min.js → /assets/app-abc123def456.min.js
(バージョン変更時のみ新URL)
Load Balancer(ロードバランサ)
複数のバックエンドサーバへリクエストを振り分け。
L4(Layer 4)Load Balancer
IP・ポート情報でみ振り分け(TCP/UDPポート)。高速だが、アプリケーション内容は見ない。
クライアント1 → LB → サーバA
クライアント2 → LB → サーバB(ラウンドロビン)
実装:Linux IPVS,Maglev(Google),など。
L7(Layer 7)Load Balancer
HTTPヘッダ・パス・ホスト名などアプリケーション情報で振り分け。
GET /api/* → バックエンドAPIサーバ群
GET /static/* → キャッシュサーバ
GET /admin* → 管理者向けサーバ
実装:nginx,HAProxy,AWS ALB,など。
ヘルスチェック
LBが定期的(例5秒ごと)に各サーバへヘルスチェック
GET /health HTTP/1.1
返却200 OK → サーバは健康
返却エラーorタイムアウト → サーバを一時除外
ファイアウォールとVPN
ファイアウォール
ネットワーク・エッジでパケットを検査・フィルタリング。
Stateless Firewall
各パケットを個別に検査。
ルール例:
- 外部 → 内部:TCP port 80・443のみ許可
- 内部 → 外部:すべて許可
高速だが、フロー単位の判定ができない。
Stateful Firewall
通信状態を追跡し、確立された接続は許可。
ステップ1:クライアント → サーバ(TCP SYN)
Firewall:「新規接続」として記録、許可
ステップ2:サーバ → クライアント(TCP SYN-ACK)
Firewall:「応答パケット」として記録済み接続の一部と認識、許可
ステップ3以降:通常許可(状態テーブルに基づく)
NGFW(Next-Generation Firewall)
さらにHTTP・HTTPS・DNSなどアプリケーション層まで検査。
検査項目:
- URLカテゴリ(ブロックリスト)
- マルウェア署名
- 異常なアプリケーション動作
VPN(Virtual Private Network)
公開ネットワーク上に暗号化トンネルを構築。
IPsec
IPレイヤーでの暗号化。
トランスポートモード(エンドツーエンド)とトンネルモード(ゲートウェイ間)。
WireGuard
シンプル・高速のVPN。最小限の暗号化情報で完全な秘密性を実現。
設定例:
[Interface]
PrivateKey = ...
Address = 10.0.0.1/24
ListenPort = 51820
[Peer]
PublicKey = ...
AllowedIPs = 10.0.0.2/32
OpenVPN
ネットワーク仮想化
VXLAN(Virtual Extensible LAN)
L2ネットワークをL3のトンネルで拡張。
データセンタ間でL2セグメントを仮想的に拡張する際に使用。
Geneve(Generic Network Virtualization Encapsulation)
VXLANより柔軟で、拡張性が高い。
GRE(Generic Routing Encapsulation)
任意のプロトコルをトンネル化。
ゲートウェイ冗長化とリンク冗長化
実際のネットワークでは、「1台壊れたら終わり」を避けるために、デフォルトゲートウェイやアップリンクを冗長化します。ここで重要なのは、ただ2本つなげばよいわけではなく、ループ防止・役割分担・切り替え時間まで含めて設計することです。
VRRP(Virtual Router Redundancy Protocol)
複数のルータやL3スイッチが、1つの仮想IPアドレスを共有してデフォルトゲートウェイを提供する仕組みです。クライアントは物理機器ではなく仮想IPを見ているので、アクティブ機が落ちても待機系へ切り替えられます。
- 平常時は1台が仮想IPを引き受ける
- 障害時は待機系が引き継ぐ
- ゲートウェイ冗長化の代表例で、L3の可用性設計を考える入口になる
リンクアグリゲーション(LACP)
複数の物理リンクを1本の論理リンクとして束ねる仕組みです。帯域増加と冗長化を同時に狙えます。
- 1本切れても残りで通信継続しやすい
- STPによる単純なブロックより帯域を有効活用しやすい
- ただし1セッションが常に全リンクを均等利用するとは限らず、ハッシュ方式の理解が必要
冗長化で見るべき観点
- 切り替え時間はどれくらいか
- 上位/下位装置との依存関係はどうなっているか
- 監視で「半壊」を検知できるか
- 冗長にした結果、ループやブラックホールを作っていないか
ネットワーク運用の基礎
ネットワークは「つながる」だけでは不十分で、状態を観測し、時刻をそろえ、障害をあとから追えるようにすることが重要です。
SNMP
SNMPは、ネットワーク機器の状態や統計情報を取得するための基本的な管理プロトコルです。
- インターフェースのup/down
- トラフィック量
- エラーカウンタ
- CPU / メモリ使用率
といった情報を、監視システムから定期的に収集できます。
運用では、単に「死活確認」するだけでなく、
- エラー増加
- 片系リンクだけの利用率上昇
- 廃棄パケットの増加
のような兆候を追うのが有効です。
Syslog
Syslogは、機器が出すイベントログを集約する仕組みです。
- インターフェース断
- ルーティング隣接の切断
- VRRPの切替
- ACL / Firewallのdeny
などを中央に送っておくと、障害後の追跡がかなりやりやすくなります。
要点は、
- 各機器ローカルだけに残さない
- 重大度を意識して扱う
- 監視通知とログ保全を分けて考える
ことです。
NTP
時刻同期は軽視されがちですが、障害解析では非常に重要です。
- ルータのログ時刻
- ファイアウォールのログ時刻
- アプリケーションのログ時刻
がずれていると、因果関係の復元が難しくなります。
そのため、ネットワーク機器、サーバ、監視基盤で同じ時刻源を使う設計が基本です。TLS証明書検証や認証基盤でも、時刻ずれは実害につながります。
監視・ログ・時刻同期はセットで考える
ネットワーク運用の最小セットは次です。
この3つがそろうと、障害の「起きた / 直った」だけでなく、いつ、どこで、何が先だったかを追えるようになります。
ネットワーク観測とトラブルシューティング
tcpdump
ネットワークインターフェースのトラフィックをキャプチャ・表示。
# すべてのパケットをキャプチャ
tcpdump -i eth0
# DNSトラフィックのみ
tcpdump -i eth0 'port 53'
# ホスト192.0.2.1との通信
tcpdump -i eth0 'host 192.0.2.1'
# HTTP・HTTPS
tcpdump -i eth0 'port 80 or port 443'
# ファイルに保存・再生
tcpdump -i eth0 -w capture.pcap
tcpdump -r capture.pcap
Wireshark
tcpdumpのビジュアル版。パケットを詳細に解析。
UI:
- Packet List(キャプチャ一覧)
- Packet Bytes(16進数表示)
- Packet Details(レイヤ別の解析)
フィルタ例:
ip.src == 192.0.2.1
tcp.port == 443
http.request.method == "GET"
ss(socket statistics)
ソケット・ネットワーク接続の統計。netstatの改良版。
# すべての接続
ss -tunap
# TCP listening
ss -tlnp
# 統計情報
ss -s
netstat(deprecated)
# ルーティングテーブル
netstat -rn
# 接続状態
netstat -tan
dig(DNS Lookup)
DNSクエリ。
# Aレコード取得
dig example.com
# 特定タイプ
dig example.com MX
# 再帰無しで権威サーバへ直接問い合わせ
dig @ns1.example.com example.com +norec
# traceオプションで全経路表示
dig +trace example.com
ngrep(Network Grep)
パケット内容をテキストで検索。
# HTTP GETリクエスト
ngrep 'GET ' 'tcp port 80'
# SMTPのMAIL FROMを検索
ngrep 'MAIL FROM' 'tcp port 25'
curl(HTTPクライアント)
HTTPリクエストテスト・デバッグ。
# verbose(ヘッダ含む詳細表示)
curl -v https://example.com
# HTTP/2
curl --http2 https://example.com
# HTTP/3(QUIC)
curl --http3 https://example.com
# DNS resolution時間を含め詳細表示
curl -w @format.txt https://example.com
# format.txtの例:
# time_namelookup: %{time_namelookup}\n
# time_connect: %{time_connect}\n
# time_appconnect: %{time_appconnect}\n
# time_starttransfer: %{time_starttransfer}\n
# time_total: %{time_total}\n
traceroute・mtr
ルート経路と遅延測定。
# traceroute:各ホップの応答時間
traceroute example.com
# mtr:リアルタイム・継続的
mtr example.com
HTTP/2 と HTTP/3
HTTP/2 プロトコルの革新点と実装
HTTP/2 は RFC 7540 で 2015 年に標準化され、HTTP/1.1 の複数の制限を解決しました。
HTTP/1.1 の問題点:
- Head-of-Line Blocking — 1つのリクエストが遅れると、後ろのリクエストがブロックされる
- 冗長ヘッダ — 同じヘッダが何度も送られる
- テキストベース — 解析が複雑で効率が悪い
HTTP/2 の解決策:
| 特徴 | 効果 |
|---|---|
| Multiplexing | 1つの TCP 接続で複数ストリーム並行処理 |
| Header Compression | HPACK で重複ヘッダを圧縮 |
| Binary Protocol | バイナリフレーム形式で効率化 |
| Server Push | サーバーが先制的にリソース送信 |
| Flow Control | ウィンドウベースで送信量を制御 |
バイナリフレーム構造(RFC 7540 Section 3.4):
+-----------------------------------------------+
| Length (24) |
+---------------+---------------+---------------+
| Type (8) | Flags (8) |
+-+-------------+---------------+-------------------------------+
|R| Stream Identifier (31) |
+=+=====================================================+=========+
| Frame Payload (0...) ...
+-------------------------------------------------------+-------+
フレームタイプ:
実装例(Node.js spdy モジュール):
const spdy = require('spdy');
const fs = require('fs');
const options = {
key: fs.readFileSync('./server.key'),
cert: fs.readFileSync('./server.crt'),
};
const server = spdy.createServer(options, (req, res) => {
// Server Push: style.css を先制的に送信
res.push('/style.css', {
status: 200,
method: 'GET',
request: { accept: '*/*' },
response: { 'content-type': 'text/css' }
}, (err, pushStream) => {
if (!err) {
pushStream.end(fs.readFileSync('./style.css'));
}
});
res.writeHead(200, { 'Content-Type': 'text/html' });
res.end(fs.readFileSync('./index.html'));
});
server.listen(3000);
参考: RFC 7540 “Hypertext Transfer Protocol Version 2”、Ilya Grigorik “High Performance Browser Networking”
HTTP/3 と QUIC プロトコル
HTTP/3(RFC 9114)は UDP ベースの QUIC トランスポート層(RFC 9000)を採用し、さらなる高速化を実現します。
HTTP/2 が残した問題:
QUIC(RFC 9000)による改善:
| 特徴 | 効果 |
|---|---|
| UDP ベース | カスタム輻輳制御が可能 |
| 0-RTT | 事前の鍵情報で TLS ハンドシェイク回数削減 |
| Connection ID | IP 変更でも接続を保持(モバイル最適化) |
| パケット番号間隔 | パケット損失と再送タイムアウトを分離 |
QUIC ハンドシェイク(Initial パケット例):
Client → Server: Initial パケット (暗号化された Client Hello)
Server → Client: Initial パケット (Handshake Secret 含む)
Client → Server: Handshake パケット
Server → Client: Handshake 完了 + 1-RTT データ開始
結果として、通常は 1 往復 で HTTP/3 通信開始。比較して HTTP/2 over TLS は 3 往復。
HTTP/3 実装例(Cloudflare の quiche ライブラリ):
use quiche::{Connection, Config};
let mut config = Config::new(quiche::PROTOCOL_VERSION)?;
config.set_application_protos(b"\\x02h3\\x02h3-29")?;
let mut conn = Connection::new_with_transport_params(
&scid,
&dcid,
&local_addr,
&peer_addr,
&config,
)?;
// データ送受信
let stream_id = conn.stream_send(0, b"GET / HTTP/3", true)?;
ブラウザ互換性と展開状況(2024年時点):
- Chrome 99+, Firefox 111+, Safari 17+ で対応
- 主要 CDN (Cloudflare, Akamai) でサポート
- YouTube, Google, Facebook など大規模サービスで利用
参考: RFC 9000 “QUIC: A UDP-Based Multiplexed and Secure Transport”、RFC 9114 “HTTP/3”、Cloudflare “HTTP/3 explained”
gRPC と Protocol Buffers
gRPC は Google が設計した高性能 RPC フレームワークで、Protocol Buffers(protobuf)でインターフェース定義をします。
REST API との比較:
| 項目 | REST | gRPC |
|---|---|---|
| 基盤プロトコル | HTTP/1.1, HTTP/2 | HTTP/2 |
| データフォーマット | JSON (テキスト) | Protocol Buffers (バイナリ) |
| シリアライズ効率 | 低(人間可読) | 高(バイナリ) |
| リアルタイム双方向 | Polling, WebSocket | ネイティブ (Streaming) |
| 開発者体験 | 単純、ブラウザで検査容易 | 型安全、コード生成 |
Service Definition 例:
syntax = "proto3";
package user;
service UserService {
rpc GetUser(GetUserRequest) returns (User) {}
rpc ListUsers(ListUsersRequest) returns (stream User) {}
rpc CreateUser(CreateUserRequest) returns (User) {}
}
message User {
int32 id = 1;
string name = 2;
string email = 3;
}
message GetUserRequest {
int32 user_id = 1;
}
コード生成とサーバー実装:
# proto ファイルから Go コード生成
protoc --go_out=. --go-grpc_out=. user.proto
type server struct {
// user.UnimplementedUserServiceServer を埋め込む
}
func (s *server) GetUser(ctx context.Context, req *GetUserRequest) (*User, error) {
// DB クエリ等
return &User{
Id: req.UserId,
Name: "John",
Email: "john@example.com",
}, nil
}
// サーバー起動
lis, _ := net.Listen("tcp", ":50051")
grpcServer := grpc.NewServer()
RegisterUserServiceServer(grpcServer, &server{})
grpcServer.Serve(lis)
Streaming パターン:
- Unary: 単一リクエスト → 単一レスポンス
- Server Streaming: リクエスト → 複数レスポンス(チャンク)
- Client Streaming: 複数リクエスト → 単一レスポンス
- Bidirectional Streaming: 双方向リアルタイム通信
参考: gRPC 公式ドキュメント、“Protocol Buffers” リファレンス、Cloudflare “gRPC over HTTP/2”
性能チューニングと最適化
TCPウィンドウサイズチューニング
TCPウィンドウは帯域と遅延に合わせて最適化。
理想的なウィンドウサイズ = 帯域幅(bps)× RTT(秒)
例:100 Mbps・100 ms RTT
→ 100,000,000 × 0.1 / 8 = 1,250,000バイト(約1.2 MB)
設定:
$ sysctl -w net.ipv4.tcp_window_scaling=1
$ sysctl -w net.core.rmem_max=134217728
RPS(Receive Packet Steering)・RFS(Receive Flow Steering)
マルチコアCPUで受信パケットを複数コアに分散。
RPS(IP tupleハッシュでCPUに割り当て):
# コア0・1・2・3で4コアcase
echo "f" > /sys/class/net/eth0/queues/rx-0/rps_cpus
(16進f = 0b1111 = 4コア)
RFS(同一フロー内のパケットを同一CPUで処理、キャッシュ効率向上):
echo 32768 > /proc/sys/net/core/rps_sock_flow_entries
NICオフロード機能
NICがパケット処理の一部を担当。
- TSO(TCP Segmentation Offload):
大きなパケットをNICが1500B単位に分割
- LRO(Large Receive Offload):
複数のパケットをNICが1つに結合
- Checksum Offload:
チェックサム計算をNICで実施
有効化:
ethtool -K eth0 tso on gro on gso on
BBRによる高遅延リンク最適化
BBRは衛星・海外リンクなど遅延が大きい環境で特に有効。
TCP Reno vs BBR(遅延100ms、帯域10 Mbps、バッファ小さい)
Reno:
CWND = 32 → パケット損失 → CWND = 16(スループット落ちる)
BBR:
帯域幅10 MbpsとRTT 100msから自動計算
CWND = 125 KB(10 Mbps × 0.1s)で安定
(パケット損失なし・スループット維持)
現在の動向
Multipath QUIC
複数のネットワークパス(WiFi + LTE)を同時利用し、片方が遅くなったら自動切り替え。
WiFi(速いが不安定) + LTE(安定)
→ QUICがパケットを両方に分散
→ 片方失敗時の遅延・再送削減
HTTP/3・QUICの急速普及
2024年末時点で、Cloudflare・Google・Facebookなどトップサイトの30-40% がHTTP/3対応。
Post-Quantum TLS
量子コンピュータ攻撃への耐性を持つ暗号化へ移行。NISTが標準化候補を発表(2022-)。
現在:RSA 2048など離散対数問題ベース
現在:ML-KEMなど耐量子暗号への検証・移行期
IPv6の加速
IPv4アドレス枯渇により、IPv6採用が加速。
2024年時点:
- Google:利用者の50% がIPv6
- トランスポート層でのIPv6トラフィック:30-40%
eBPFによるネットワーク高度化
カーネル空間でプログラム可能なBPF VMにより、ファイアウォール・ロードバランサ・トレーシングをユーザー空間で実装。
XDP(eXpress Data Path):
NIC直後でパケット処理(前方エラー制御)
tc(traffic control):
いろいろな制御ポイントでBPFプログラム実行
AF_XDP:
ユーザー空間で高速パケット処理(DPDKに近い)
io_uringによる非同期I/O効率化
従来のepoll・selectより、バッチ処理でシステムコール削減。
epoll_wait(context switchコスト)× 100クライアント
↓
io_uring(共有リングバッファで1 context switch)
→ 数倍高速化
5G・6G・衛星通信の融合
Starlinkなどの衛星通信が遅延20-40msまで改善し、5Gと組み合わせたハイブリッド通信が現実化。
低遅延:地上5G
カバレッジ広い:衛星通信
エッジ遅延:衛星 → キャッシュサーバ → ユーザー
補足
第7章 ネットワーク
Web、API、動画配信、チャット — すべてネットワークの上で動いています。本章は「なぜ層に分けるのか」「TCPとUDPの違い」「DNSとHTTPの関係」を押さえ、トラブル時に「どの層が怪しいか」を切り分けられるようになるのが目的です。
ネットワークは、層ごとに役割を分けることで複雑さを扱いやすくしています。本章ではDNS、TCP、TLS、HTTPがどうつながるかをひとつの流れで理解します。
この章が実務で役立つ場面
7.1なぜ層に分けるのか
ネットワークは複雑なので、役割ごとに層に分けて考えます。
【図18】TCP/IP階層モデル:
7.2パケットという考え方
データは一度に巨大な塊で運ばれるのではなく、パケットという小さな単位に分かれて送られます。
これにより、
- 分割送信
- 再送
- 経路選択
がしやすくなります。
7.3 TCPとUDP
TCP
- 信頼性重視
- 順序保証
- 再送あり
- コネクションあり
TCPはアプリケーションに対して、信頼できる順序付きのバイトストリーム を提供します。ここで大事なのは、「メッセージ単位」ではなく「バイト列単位」だという点です。送った write() 1回ぶんが、そのまま1回の read() に対応するとは限りません。
UDP
- 軽量
- 順序保証なし
- 再送なし
- コネクションなし
UDPは最小限の仕組みでデータグラムを送ります。配送保証や重複防止は標準では持たないので、必要ならアプリケーション側で補います。
7.3.1再送と輻輳制御
TCPが「信頼できる」ように見えるのは、ただ再送するからだけではありません。ネットワークが混んでいるときに、自分の送り方を抑える 輻輳制御も重要です。
もし全員が「落ちたからもっと送る」を繰り返すと、ネットワーク全体がさらに詰まります。そこでTCPは、届き方を見ながら送信速度を調整します。
ここで見るべきなのは、
- 損失
- RTT
- 再送
- ウィンドウサイズ
の関係です。Webの遅さが、アプリではなくネットワーク輻輳から来ることもあります。
7.3.2フロー制御と輻輳制御の違い
この2つは名前が似ていますが、見ている相手が違います。
前者は「相手が飲み込めるか」、後者は「道が渋滞していないか」を見ています。
この違いがわかると、TCPが単に「丁寧な配送」ではなく、送信側・受信側・経路の三者を見ながら振る舞う仕組みだと見えてきます。
7.4 IPアドレスとルーティング
IPは「どこへ送るか」を扱い、ルータはパケットを次へ転送します。
ルーティングの直感は、「目的地までの次の一歩を選び続けること」です。
【図18-2】クライアントからサーバへ届くまで:
7.5 DNS
人間向けの名前をIPアドレスへ変換する仕組みです。
【図19】DNSによる名前解決:
DNSは単なる「電話帳」ではなく、木構造の名前空間として設計されています。www.example.com は1つの塊ではなく、ラベルの列として扱われます。この見方があると、サブドメイン、委任、ゾーンという概念も理解しやすくなります。
【図20】DNSの木構造(名前空間):
7.6 HTTPの流れ
Webでは大まかに次の流れで通信します。
HTTPはstatelessなrequest/responseプロトコルです。つまり、基本形では「1回のリクエストに対して1回のレスポンスを返す」ことを中心に考えます。ログイン状態や買い物かごのような継続的な状態は、Cookieやセッション、トークンなどを使って別途表現します。なお、上の流れはWebブラウジングでよく見る典型例で、後述のHTTP/3では運び方がTCPではなくQUIC / UDPになります。
【図20-2】ブラウザでページを開くまでの流れ:
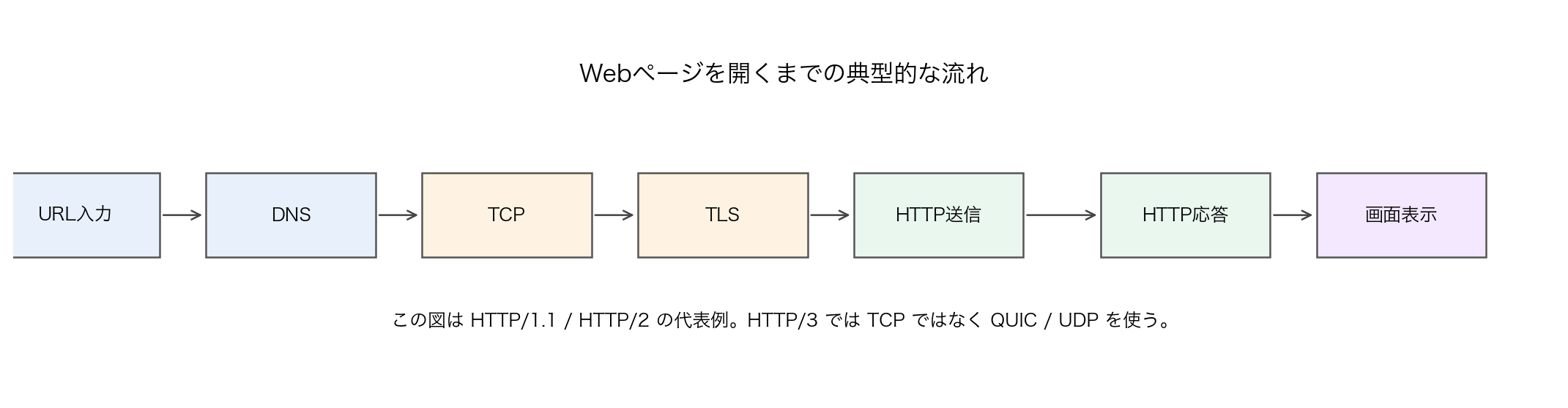
7.6.1 HTTP/1.1とHTTP/2
HTTPの「意味」は共通でも、運び方には世代差があります。
- HTTP/1.1: メッセージ構文、フレーミング、接続管理が重要
- HTTP/2: 同じ意味を、より効率のよいフレーム化と多重化で運ぶ
HTTP/2では接続がpersistentで、1本の接続の上で複数のやり取りを効率よく流せます。なので「HTTP/2はHTTPの意味が変わる」というより、「HTTPの意味は保ったまま、運び方が洗練された」と見るのが自然です。
【図21】HTTPセマンティクスとトランスポートの関係:
7.6.2ロードバランサ、プロキシ、CDN
実際のWebシステムでは、クライアントがいきなりアプリ本体へ到達するとは限りません。間に、
が入ることが多いです。
これらはそれぞれ、
- 入口を一本化する
- 複数サーバへ振り分ける
- 静的コンテンツを利用者の近くで返す
という役割を持ちます。
なので「HTTPの問題」と見えても、実際にはCDNのキャッシュ設定やロードバランサのヘルスチェックが原因、ということもあります。
7.7ソケット
アプリケーションがネットワークを使う入口がソケットです。
- 送信先を指定する
- 接続を張る
- データを送る / 受ける
ソケットは「ネットワーク版のファイル記述子のような窓口」と見るとイメージしやすいです。実際、Unix系では read / write に近い感覚で扱える場面が多く、OSのファイルI/OとネットワークI/Oの設計思想がつながっています。
7.8 TLSは何を足しているか
TLSは、通信路の上に
- 盗み見されにくさ
- 改ざん検出
- 相手確認
を足します。HTTPSは「HTTP over TLS」と見るとわかりやすいです。
TLS 1.3(RFC 8446、2018年)の主な改善:
- ハンドシェイク1-RTT:初回接続の待ち時間を半減
- 0-RTT:再訪問時に即座にデータ送信(リスクあり)
- 古いアルゴリズム削除:RC4、3DES、SHA-1、RSA鍵交換を除去
- 前方秘匿性(PFS)必須:鍵漏洩時の過去通信保護
7.9 HTTP/3とQUIC
2022年RFC 9114で標準化された HTTP/3 は QUIC プロトコル(RFC 9000)の上に構築される。QUICはTCPの代替で、以下の特徴を持つ:
- UDP上に構築:カーネル実装を待たずユーザ空間で進化可能
- TLS 1.3統合:暗号化は必須、ハンドシェイクを1-RTTに削減
- head-of-line blockingの解消:TCPは1パケット遅れで全部詰まるが、QUICはストリーム単位で独立
- 接続マイグレーション:IPアドレスが変わっても接続維持(モバイル向け)
7.10レイテンシとスループット
- レイテンシ: 1回の往復の遅さ
- スループット: 単位時間あたりの量
この2つは別物です。帯域が太くても最初の応答が遅いことはあります。
7.11ミニ比較表
| 概念 | 何をするか | 混同しやすいもの | 違い |
|---|---|---|---|
| TCP | 信頼性ある転送 | UDP | 順序保証と再送がある |
| IP | 宛先へ届ける | DNS | DNSは名前解決 |
| DNS | 名前をIPへ変換 | HTTP | HTTPはアプリ通信 |
| レイテンシ | 1回の遅さ | スループット | 量ではなく時間 |
7.12よくある誤解
DNSは「通信そのもの」ではありません。通信の前に、どこへ送るかを調べる仕組みです。
7.13例題
【図22】ネットワーク問題の切り分け手順:
例題1: example.com を開く前にDNSが必要な理由を述べよ。
解説: 名前からIPアドレスを知る必要があるからです。
解説: 順序保証と再送による信頼性です。
7.16ユースケース
Web API
動画配信
- スループット重視
- 再送より連続再生が大事な場面もある
まとめ
ネットワークは、層ごとの役割を押さえつつ、実際の通信を一本の流れとして追うことが大切です。DNS、TCP、TLS、HTTPをつなげて理解すると、設計にもトラブルシューティングにも強くなれます。
参考文献
公式・標準
- RFC 1034: Domain Names - Concepts and Facilities
- RFC 768: User Datagram Protocol (UDP)
- RFC 8446: TLS 1.3
- RFC 9000: QUIC
- RFC 9110: HTTP Semantics
- RFC 9112: HTTP/1.1
- RFC 9113: HTTP/2
- RFC 9114: HTTP/3
- RFC 9293: Transmission Control Protocol
- RFC 9293: Transmission Control Protocol (TCP)
- MDN: HTTP
- IETF QUIC Working Group